numeric variables을 factors로 만든다는 것의 의미는 무엇일까?
R Commander에서 어떤 결과를 만들어내는 것일까?
=========================================
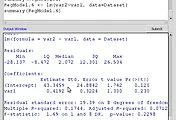
R Commander - Statistics - Summaries 에는 여러가지의 기술통계적 요약을 만드는 기능이 있다.

화면 아래의 Output Windows에 보이는 것처럼 요약 정보들이 추출된다.
> summary(Dataset)
X1
Min. :1.00
1st Qu.:2.00
Median :3.00
Mean :2.87
3rd Qu.:4.00
Max. :5.00
NA's :5.00
> numSummary(Dataset[,"X1"], statistics=c("mean", "sd", "quantiles"),
+ quantiles=c(0,.25,.5,.75,1))
mean sd 0% 25% 50% 75% 100% n NA
2.87013 1.194068 1 2 3 4 5 385 5
하지만, 자료의 숫자들 1, 2, 3, 4, 5 는 어떤 의미를 지니고 있는 범주일 경우가 일반적이다.
1) 1학년, 2학년, 3학년, 4학년, 5학년
2) 각 학교에서 1등급, 2등급, 3등급, 4등급, 5등급 (여러학교에서 선발된 학생들의 각 학교별 성적)
3) 초등학교졸업, 중학교졸업, 고등학교졸업, 대학교졸업, 대학원 이상 졸업
4) 사원, 주임, 대리, 과장, 차장
단순한 숫자를 '숫자로 기호화된 의미있는 요소들'로 변환시키는 작업이 'convert numeric variables to factors'.
이 변환(Dataset$X1 <- factor(Dataset$X1, labels=c('1','2','3','4','5')) 뒤에 생산되는 기술통계의 자료들은 다음과 같다.
> summary(Dataset)
X1
1 : 43
2 :138
3 : 65
4 :104
5 : 35
NA's: 5
> .Table <- table(Dataset$X1)
> .Table # counts for X1
1 2 3 4 5
43 138 65 104 35
> round(100*.Table/sum(.Table), 2) # percentages for X1
1 2 3 4 5
11.17 35.84 16.88 27.01 9.09
각 숫자화된 요인들의 빈도와 구성비율(%)을 확인가능하다. 아울러 그래프로 그 정보를 추출할 수 있게 된다.
그렇다면, 이러한 변환 작업은 왜 필요할까? Spreadsheet (예, excel화일)로 저장된 정보를 .csv 또는 .txt 등으로 변환하는 과정에서 요인적 의미들이 상실되기 때문에 다시 그 의미를 되살리는 것이다.
(일반적으로 excel에서는 블록을 씌우는 방법(일부분선택)으로 계산을 한다.)
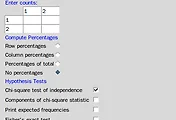
5. Convert numeric variable to factor...
데이터 > 활성 데이터셋의 변수 관리하기 > 수치 변수를 요인으로 변환하기... Data > Manage variables in active data set > Convert numeric variable to factor... 수치 변수를 요인으로 전환해야 하는 경우..
rcmdr.kr